Why you should never let developers run wild in public clouds.
One of the problems with public clouds is public accessibility. This doesn’t sound so dangerous, but it could quickly become an issue if you allow developers to configure and generate resources in public clouds without taking the time to understand who can access it. I’m going to refer to a drawing that’s a derivative of an application I’ve seen in real life to show you what the issues could have been.
Context
The company in question wanted a customer portal where they wanted data to be collected and processed from an SQL database on premises by an Azure Data Factory instance, and then forward the processed data to an Azure SQL server. From there, the application will read the SQL data and present it in an easy and accessible way to the logged in customer. The project drawing was like this:

And if you’re new to public clouds, you may respond to this application drawing with questions like: Why’s this a problem? Why are you complaining about this?
I’d love to say there’s nothing wrong with this configuration, but the reality is the same with most of the public cloud providers: If you don’t need the functionality, you need to close it down yourself. All resources (in the default configuration) are set up with all services supported. A virtual network for instance use Class A networks: 10.0.0.0 with a /16 bit block. This allows for just over 65 000 IP addresses. This is an incredible size, considering most companies will never create more than 100 virtual machines, and if you do, you know more about the network than going with the default. Equally, an Azure SQL Server is publically available from all networks at the point of creation.
Let me show you some of the attack vectors for the application drawing above:

I’m going through these starting from the offices and moving our way through the application towards the perimeter security. Offices: The application used Microsoft Integration Runtime over the open internet. This means the Data Factory authenticates with the on premises SQL server with hard-coded credentials and transfers the full customer database (with usernames, invoicing information and other private data) over the open web. The data is encrypted in transit using TLS 1.2 encryption of cause, but the data is in jeopardy all the same. In addition to this you’re opening up with a firewall rule between the data factory and the on-premises environment to allow the Integration Runtime to trigger the export.

Next, we’re moving on to where the Data Factory keeps data between processing and uploading to the Azure SQL database; the Storage Account – Container. The Storage Account did not have any restrictions on access, no firewall and no identity management or anything. The system used a managed private endpoint, allowing the Data Factory to interface with the account. This means the data factory resource didn’t need to log in, but could programmatically call any function of the storage account using a service-to-service connection. This may sound like an issue, but is actually a great way to communicate, as it keeps the communication inside Microsoft’s network, and doesn’t touch the open web. The issue stems from the potential of compromised users, where any compromised user with privileges to the account will be able to connect to the Storage Account from anywhere in the world and get a hold of a copy of the raw customer data directly from there.
Moving on to the Azure SQL server, we’re looking at the SQL server firewall and how communicating with it works. From the back and out, the server doesn’t have any Azure AD or AD integration activated, meaning the server only have one administrator account and/or an SQL administrator. The application had no TLS requirement, and allowed SQL authentications. SQL authentication does not by default have timeouts or lockout structures – and is often left un-monitored by security teams. This means an attacker who found the server name (seen below) could simply brute-force the username and password with little to no recourse for the organization. Security teams often monitor the perimeter (public network facing) devices instead of internal resources. In Azure however, all publicly available resources are in almost the same situation as if you were putting them in the DMZ, but this is a concept often left misunderstood. In classic data center theory, you’d do a lot of work securing any device in the DMZ, as it is more exposed to threat because of the lack of or slightly more permissive firewall configuration and inspection levels.
Side note: DMZ
The DMZ is commonly where you put public facing devices who need to be accessible from the public internet. Consider File Transfer, web and mail servers. These are usually logged on to from the internet. You don’t want to route users behind your primary firewall, so you put the servers onto the “De-Militarized Zone” where you have less filtering or more permissive rule sets. If any of these servers are compromised, the attacker will not have direct access to your company’s local network, because they need to traverse the firewall and more restrictive rule sets.

From the publicly available application, we’re seeing several issues:
– Application authenticates with SQL Server over public endpoint, passing user account information and data from the application to the SQL server over the web.
– Application has connection string and SQL administrator credentials found in clear text in the code base.

So how do we fix it?
Microsoft has a beautiful site here, where they create beautiful “starter” designs for all kinds of different applications, structures and functions. We’re going to use one of these (this one) as a starter for a redesign for our application. The first part of the process is to move the resources from public to private and anchor them to a network. Here’s the design I came up with:

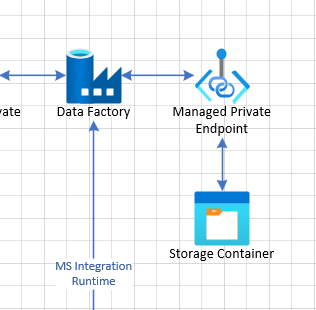
Taking you through the drawing, we’ll start in the Data Factory network. The resource Data Factory actually consist of several different resources and a unified web-front-end. I’ve drawn it up here:

Data Factory consists of a private-link structure, a managed virtual network, compute resources, storage accounts, SQL databases and service bus resources, all anchored to a single managed network behind a management portal.
Just because I love to look into what the different things do:
– Private Link engine: Provides a simple access structure to interface with other technologies in Azure, on-premises, AWS, Oracle and Google clouds.
– Managed Virtual Network: Provides a common network structure for everything to communicate isolated from the public network and endpoints.
– Virtual Machine pools: Provides RAM and processing capabilities for pipelines and runs.
– Storage accounts: Provide information storage, and swap functionality for large data-sets.
– SQL databases: Provide schema storage for processing and correlation of table data.
– Service Bus: Provide temporary storage in case of large data sets and advanced processing requirements.
The combination of services and private link capabilities allows the Data Factory resource to interface with almost any system in IT today. Microsoft has this picture to show some of the integration features available for the Data Factory today:

There’s a design function included in how this resource is constructed however; as the resource is in it’s own network, it’s not super simple to integrate it with different resources using private endpoints (and anchor it to a different virtual network). To anchor the Data Factory to a resource you’ll need to configure the private endpoint in the “Linked Services” panel, using managed private endpoints:

On the resource side you’ll have to approve the managed private endpoint before the link is created:

However, Azure Data Factory will in standard configurations use public endpoints to connect directly to the resource requested.
You’ll see an example of a public endpoint in an Azure SQL Server for instance:

As you can tell, the server has a server name exposed to the internet (obvious because of the .net ending). The server name is an A record under the database.windows.net domain, allowing Microsoft to change the A record to reflect the public front end should the available loadbalancers or other resources fail. This minimize effort on Microsoft’s end. A records are a Domain name function to translate a name to an IP address. This is done to allow you as a human to remember vg.no instead of 195.88.54.16. You can test it yourself by opening cmd and writing the following:
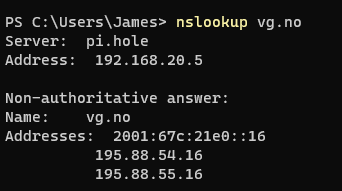
We can test whether the SQL server is currently responding to requests by issuing the following command:
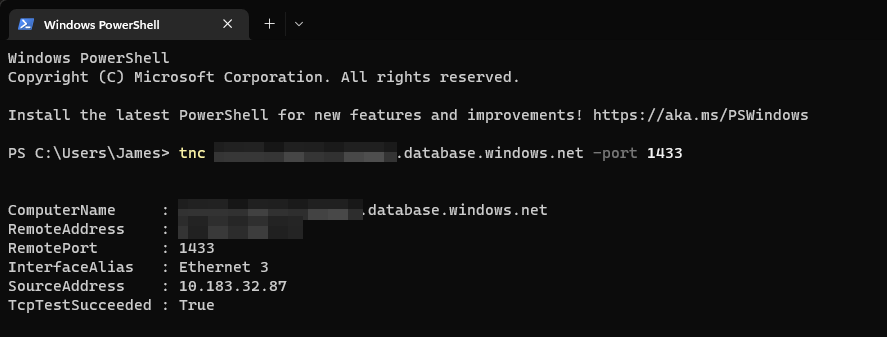
This test-request uses powershell’s “Test-NetConnection” function with the full address + the standard SQL port of 1433. When you receive the TCPTestSucceded, you’re getting a successful connection. This does not necessarily mean you’re going to get authenticated, but the connection responds with SYN ACK when you’re requesting the connection. This means something is listening on the port on the server.
A short side note about how TCP / UDP connections work
There are two main types of connections you can use in networks: TCP and UDP.
Transmission Control Protocol – Also known as connection oriented communication. This roughly means your computer starts a connection with the other device, be it a web, mail or file transfer server, and the server accepts the connection by confirming back to your computer. This is known as the 3-step TCP handshake process.

This seems daunting, but is secretly really simple. The client asks for the connection using the SYN step (Synchronize Sequence Number), the receiving server responds with a SYN,ACK message (Synchronize Sequence Number, Acknowledge). The client have to return a ACK message (Acknowledge) before the connection is fully established. There’s another three step process for closing the connection again, but that’s not important in this context. In the question of the Test-NetConnection powershell function, we’re sending SYN from the client computer, to the receiving device on the port defined, and if the client receives a SYN,ACK in return, the test is successful. The connection is never established, because an ACK is never returned to the server.
The reason most of the internet use this connection method is because it will ask for packages from each side of the connection again if they are received damaged, and will sort them if they are received out of order. This makes the connection method wonderful for web, email and file transfer traffic, but useless for phone calls and TV signals who’re sensitive to package failures.
With UDP (User Datagram Protocol) it’s a more of a throw data to another participant. The normal definition of UDP is connection-less transmission. This is in addition why most traditional Denial-Of-Service attacks are UDP transmission based. The sender does not care whether or not the recipient accepts the messages. The packages are generated and sent, with no regard. This is wonderful for systems who require quick transmission with minimal latency like phone calls and TV signals. If a package fails, you’re more happy with a stutter in the phone call than the entire call stopping to play you a sound from three or four milliseconds ago and then resume with everything that’s been received after that sound afterwards to catch up. This would make a very uncomfortable call experience. With UDP however, the missing sound-bit would just not be played, and when it’s received out of order, it’d be discarded.

Back to public endpoints
When we’re looking at endpoints from the Managed Virtual Network there are two types:
– Public endpoints; traversing internet using a domain lookup and public IP addresses.
– Private endpoints; traverse local area network connections and private IP addresses.
The standard communication structure in Azure is the public endpoint structure. The reasoning for this is because it’s soooo much easier to deal with for projects that does not require proper confidentiality. When you’re using private endpoints you need to anchor the services together using a virtual network, and use internal IP addresses for communication instead of using publicly routeable addresses.
This sounds technical, but is simple when explained. You’re sending a letter from your house to a neighbor. If you’re moving out into the public road to go to your neighbor’s door, you’re using public endpoints. If you instead move your neighbor into your spare room and walk across the hallway from your room to his, you’re using private endpoints.

You can imagine having your resources inside of your house instead of having to move out on the public internet and back again is a better solution for communication confidentiality. It’s the same in public clouds.
So what about authentication?
Further up, I’m complaining a lot about how the applications authenticate to SQL servers. How do you do so securely? First of all; if you ever write out a username and password in clear text in your application functions, you’re doing it wrong. Take for instance the SQL server in this project (parts removed for privacy):
Server=tcp:McToastiesCrunchyToast.database.windows.net,1433;Initial Catalog=TheToastyDB;Persist Security Info=False;User ID=sqlsrvadmin;Password={your_password};MultipleActiveResultSets=False;Encrypt=True;TrustServerCertificate=False;Connection Timeout=30;
This is a connection string for the server and default catalog. If you put something like this in the code, you will quickly see your data leaked. See per example: Twitter. It’s pretty scary how bad digital hygiene can quickly land you in both hot water with GDPR and crypto-attacks. So, how do we protect against it without removing access? We use an Azure Keyvault. These resources allow applications to request secrets, certificates or connection strings using programmatic requests and passing all of the communication using TLS 1.2 encrypted https traffic.

You’ll see in the data factory, you’ll have a resource that’s integrated with your Data Warehouse if you’ve done it correctly:

The data warehouse will then be able to request information directly from the key vault in order to authenticate with the other resources. Notice how there’s a managed identity connected to the resource, which has been provided privileges in the keyvault in order to control what the service can see.
Side-note: Managed identities
There are two different types of managed identities:
– System Assigned; Is assigned directly to the resource itself. Only the resource can use this identity, and if the resource is removed, so is the identity.
– User Assigned; Is assigned as a user object which can be used by several resources. If the resource is deleted, the user is retained. User assigned identities is often used when you need specific privileges or have many resources who need to use one account together (ease of management).
Back to endpoints
I’ll provide the picture of the solution once more:
Some Platform-as-a-Service resources did not use Private Links to link back to the network. For the services listed here, that’s no longer the case, so I won’t go into further detail on the difference between a service endpoint and a private link.
What I’d like to point out however is why there are two computers in the back-end-virtual-network. The reason for this is because there’s a Load balancer taking the requests from the data warehouse and forwarding them to on-premises. The issue is how the SQL servers on premises can’t be in the back end pool of the load balancer, but Azure Compute resources can! The ones on the drawing are burstable linux virtual machines with IP tables installed, making them routers effectively, creating real high-availability between the routing of the Data Warehouse, the virtual gateway and the on premises environment.
Lastly there’s the Site-to-Site VPN. Controlling Site-to-Site connections is something coming in a later article, but the point here was to create a controlled, local connection between the cloud service and the on premises SQL servers. What we did on each end was to entirely limit what each side could see, and allowed only what needed to be allowed.

This meant the connection in is only allowed from the VPN zone to that one port on that one SQL server, restricting the data flow should any resource in the cloud become compromised.
What about the network facing applications?
This is a great question with a simple solution. The applications themselves do not need any anchoring to the network because they are supposed to be publicly available, but as the SQL Server and key-vault will refuse public communication after the redesign we needed to allow the web application access to the virtual network resources.

This allowed us to configure the back end of the application to allow outbound traffic to the other resources using their private IP addresses. We did some work and put the applications themselves behind an application gateway and activated inbound traffic restrictions to enforce request inspection and SSL offloading.

Side Note: SSL Offloading: The process of enforcing the communication encryption on the front of the application instead of letting the web application do it itself. The reasoning for this is usually because encryption is processor intensive work, and the application should not be burdened with that kind of thing. In addition, if the communication between the security layer, the application and the application resources is unencrypted, it allows for easier inspection of the traffic.
What should you consider
- What kind of confidentiality does my application require?
- Am I comfortable with my data traversing the open internet?
- Do I have good “enough” digital hygiene?
- Do I need help with my architecture? If you do, you should ask for it before you publish the application.
- Have I performed a code-review to see if I’ve made any mistakes or put usernames, passwords, account keys, SAS keys or other credentials in clear text?
- If anything fails, what happens? Have I constructed my app to support High Availability (HA)?
- If anything is compromised, what will an attacker get access to?
- Where am I putting my secrets? Am I comfortable with how my application provides authentication and request sanitation?
If you’re a developer or an amateur coder, please consider asking for help (there are several of us who’d love to help) before publishing your app in an environment where it’s prone to abuse. At least consider what kind of confidentiality you require and whether your digital hygiene is good enough. I wish we didn’t have to be restrictive and difficult, but sadly that’s not the world we live in today.
Thank you for reading.
PS: I know this last article was a long time coming. My wife and I have taken in a puppy (Rhodesian Ridgeback) named Bao, and he’s been a handful. Things are however getting much calmer, so I’m writing as fast as I can.
